O co jde a k čemu to je
Práce s kvantitativními daty je nedílnou součástí analytických činností ve veřejné správě. Data management pokrývá soubor činností, které zaručují, že data jsou přehledně uložena, popsána a zpřístupněna dalším uživatelům ve formě datových produktů.
Případová studie
Tento návod jsme vyvinuli na základě práce s oddělením výzkumu a evaluací na Agentuře pro sociální začleňování.
Sebediagnostika: je to pro mě?
Tento návod se vám bude hodit, pokud pro vás platí něco z následujícího:
- Náš útvar pravidelně zpracovává datové výstupy pro interní i externí využití.
- Pracujeme s datovými zdroji od různých poskytovatelů, které následně kompilujeme do ucelených data setů
- O data se stará jeden člověk nebo několik málo lidí v týmu, ale chtěli bychom, aby zbytek týmu mohl být při využivání dat samostatnější
Jak na to
Co je cílem
- zpřístupnit a zpřehlednit data širší skupině lidí (typicky uvnitř týmu/organizace)
- mít jasno v tom, odkud se která data vzala a jak je upravujeme pro další práci
- zdokumentovat jednotlivé datové sady: co v nich je a co znamenají jednotlivé položky?
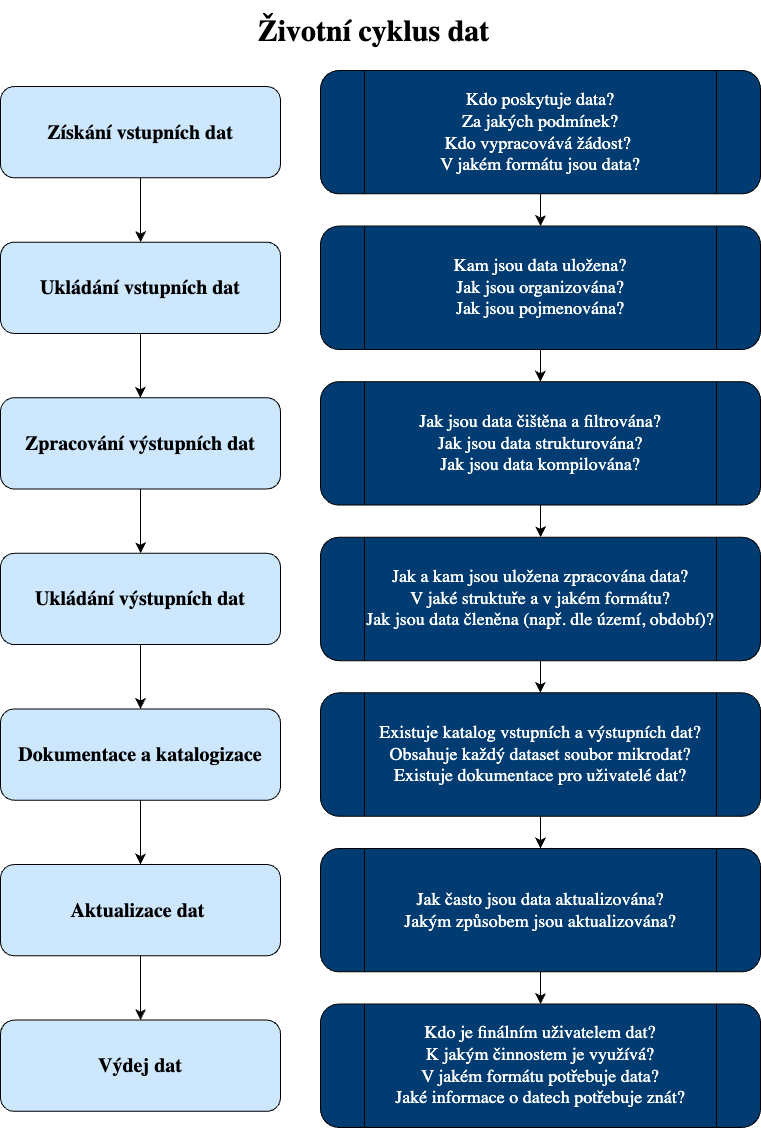
Zmapujte životní cyklus vašich dat
Nejprve rozlište a popište kroky vedoucí od získání (či generování) dat k finálnímu datovému produktu určený ke sdílení. Těmto krokům se říká životní cyklus dat.
Vytvořte tabulku, kde řádky představují každý krok v životním cyklu dat. Pro každý krok popište co se děje a kdo to vykonává.
- Získání vstupních dat (či jejich sběr)
- Ukládání vstupních dat
- Zpracování výstupních dat (čištění, strukturování, výběr, kompilace)
- Ukládání výstupních dat
- Dokumentace a katalogizace
- Aktualizace výstupních dat
- Výdej dat
Můžete také využít schéma životního cyklu dat. Níže najdete generické schéma, které můžete následně upravit podle vašich potřeb.
Zeptejte se finálních uživatelů, jak data využívají a pro jaké účely
Předtím než navrhnete způsob, jak data poskytnout finálním uživatelům, zeptejte se jich, jakým způsobem hodlají datové produkty využít a pro jaký účel. Zároveň identifikujte případné obavy a překážky, které mohou vzniknout.
Uživatelem – skutečným nebo kýženým – často budou další členové týmu nebo další lidé ve vaší organizaci. Můžou jím ale být také externí subjekty, kterým data předáváte – jiné organizace, výzkumníci aj.
Prakticky:
- udělejte si seznam všech, kteří by měli nebo chtěli přistupovat k datům, o která se staráte.
- s každým z nich - nebo aspoň těmi nejzásadnějšími - si pár minut pohovořte. Zeptejte se na nějaký nedávný příklad, kdy s daty pracovali, a zkuste identifikovat, co jim brání, jakým nejistotám čelí a jaký způsob přistupování k datům by jim vyhovoval.
- v dalších krocích pak můžete s těmito stejnými lidmi opět v pár minutách otestovat způsob přistupování k datům, případně i širší systém správy dat.
Strukturujte vaše úložiště dat
Při správě datových úložišť rozlište surová data, back-end a front-end:
- úložišťe surových dat: datové sady, které obdržíte od poskytovatele uložte v jejich surové formě spolu s dokumentací, kterou vám poskytovatel dodal.
- back-end: datové sady, které jsou strukturované podle vašich potřeb (např. sloučením několika datových sad)
- front-end: datové sady, které jsou určené k využití dalšími uživateli (interní i externí)
Prakticky:
Pokud nevidíte technickou potřebu mít vše zachycené v databázích, začněte prostě tím, že datové soubory dobře uspořádáte na sdíleném disku.
Postarejte se také o konzitentní názvy souborů - viz How to name files: aby je přečetl stroj i člověk a aby se správně řadily
Případně k tomu vytvoříte rozcestník v dokumentu, na intranetu, v Sharepointu aj. Začněte těmi sadami a soubory, které skutečně používáte.
Zdokumentujte svá data
Každá datová sada má být dokumentovaná tak, aby bylo možné dohledat základní popis datových sad a jejich proměnných.
Dokumentujte
- datové sady - ať už jako jednotlivé soubory, listy v excelu, nebo např. datové sady, které dostáváte či produkujete pravidelně
- proměnné v každé datové sadě
Lze rozlišit dva typy dokumentace dat:
- metadata: soubor popisů pro jednotlivé sady a datové proměnné
- dokumentace pro uživatele: soubor informací, které pomohou uživatelům v orientaci v datových sadách a jejich využití.
Datové sady a soubory
Prakticky:
V jedné tabulce/seznamu zachyťte datové soubory, které jsou „na vstupu“: váš sběr, vyžádaná data od jiné organizace, export z nějakého systému, atd.
Hned vedle dat pokud možno uložte jakoukoli dokumentaci, kterou k souborům máte - včetně např. dokumentu, kterým jste o data požádali a průvodní informace od poskytovatale. Pokud jsou na vstupu data od ČSÚ, uložte si jejich dokumentaci. Zachyťte i jakákoli omezení využití, která se k souboru vážou (důvěrnost, zveřejnitelnost).
V tabulce zachyťte metadata o souboru: původ dat, datum přijetí, přesnou cestu k souboru, kontakt na tvůrce/správce, časové pokrytí dat, odkaz na komunikaci s původcem dat nebo žádost o data
Ve druhém seznamu zachyťte datové soubory, které na základě těch vstupních vytváříte vy. Často půjde o sumáře, propojení tabulek, výběry… Zde zachyťte
Pokud vytváříte ještě další produkty „na výdeji“ (pravidelné exporty pro určité uživatele, náhledy, dashboardy, atd.) zachyťte je také. Obzvláště tuto kategorii je dobré mít např. v rozcestníku na intranetu
Proměnné v datech
Následně u zásadních datovýh souborů zdokumentujte klíčové proměnné. Je na vás, jestli tuto dokumentaci budete držet u zdrojových souborů, u zpracovaných (back-end) dat nebo v odděleném souboru.
Optimální je, aby tento metadatový list (codebook) byl co nejblíže datům. Pokud data udržujete v Excelu, dejte jej na první dokumentační list sešitu.
Alternativy
Katalog datových položek (tzv. data dictionary)
Alternativní přístup je vytvořit velký katalog všech datových položek, které v organizace používáte, a k nim zanést jejich původ a metadata.
To se hodí zvlášť v případě, že používáte nějakou soustavu indikátorů, popř. vytváříte vlastní indikátory a indexy.
Dokumentace jednotlivých proměnných pak vypadá podobně, ale všechny proměnné jsou zdokumentované na jednom místě a dokumentace proměnných se odkazuje na dokumentaci zdrojových datových sad a souborů.
Správa metadat
U větších systémů, kde se data přebírají, propojují a zpracovávají automaticky, lze zavést systém správy metadat, kdy metadata vstupují přímo do zpracování dat a výsledný prezentační systém (např. dashboard nebo datová aplikace) může datovou dokumentaci zobrazovat vedle dat. To ale vyžaduje pokročilejší technologie a správu dat napříč organizací.
Také je možné stavět na principech propojených dat (linked data), to se ale opět týká spíš správců velkých datových fondů.
Integrace dat
Pro některé situace a využití může být vhodné data z externích zdrojů pravidelně a co nejvíce automatizovaně integrovat do jednotné databáze. Příkladem je PAQ Research, kde většinu externích dat na základě šablon a automatizovaných skriptů načítají do jedné databáze.
Nastavte proces pro výdej dat k dalšímu využití
Na základě informací od finálních uživatelů navrhněte způsob, jakým budete předávat vaše datové produkty.
Může jít třeba o excelovou tabulku, ze které budou uživatelé přímo čerpat, nebo o sofistikovanější rozhraní (např. databáze nebo dashboardy).
Pro přípravu dat k využití v organizaci se vám může hodit návod Analýza dat moderně ⟶
A pokud vaše řešení bude zahrnovat třeba dashboard nebo webové rozhraní, nahlédněte do návodu Uživatelské testování ⟶
Udržujte pořádek i uvnitř datových souborů
Při správě dat – především v Excelu – je dobré se držet několika zásad:
- Na jednom listu pouze jedna sada dat
- Na listu s hrubými daty nejsou žádné vzorce ani výpočty
- V jedné buňce pouze jeden údaj
- Tedy: data v tzv. tidy formátu (Wickham (2014); 6. kapitola Wickham, Çetinkaya-Rundel, a Grolemund (2023))
- Všechna data zanesena v buňce, nikoli formátováním
- Konzistentní názvy listů
- Konzistentní názvy proměnných
- Konzistentní názvy proměnných
- Smysluplné kódování hodnot (např. proměnná
muzs hodnotami 0 a 1 je lepší nežpohlavis hodnotami 0 a 1) - Konzistentní kódování chybějících hodnot
Data ukládejte s vypnutými filtry, s kurzorem na listu dokumentace a v datových listech vlevo nahoře.
Více viz článek pro praktiky Broman a Woo (2018) a metodiky analytické profese britské státní služby (Analysis Function Central Team, ONS 2021a, 2021b).
Na co si dát pozor aneb tipy & triky
Neutopte se v diskusích a snaze o dokonalost
Zásadní je někde začít. Dlouhé diskuse o tom, která data jsou hrubá a která už zpracovaná, nebo jestli evidovat každou novou verzi té stejné datové sady, vám nejspíš nepomůžou. Dokonalý systém neexistuje.
Začněte něčím jednoduchým – třeba jen zachyťte, jaká data často využíváte.
Rutina, nejen velký třesk
Kromě jednorázového úklidu a zdokumentování péče o data vyžaduje i změnu běžné rutiny, např. zvyknout si při přebírání dat odjinud tato data zanést do dokumentace. Ano, chvilku to zabere, ale konzistentní postupy se vyplatí, protože uspoříte čas při potýkání se s nepořádkem později a posílíte schopnost svého týmu data správně využít.
Obsahová, nejen technická dokumentace
Do péče o data a jejich dokumentaci zatáhněte ty, kdo s daty pracují nebo dobře znají prostředí, odkud se data generují. V dokumentaci můžete zachytit znalosti o specifikách daných dat, insider znalosti o tom, jak se sbírají, a zkušenost s prací s nimi: na jaké nečekané vlastnosti dat jsme přišli při práci s nimi.
Tím také posílíte péči o znalosti svého týmu: při dokumentaci dat můžete zachytit informace, které by jinak zůstaly ukryty v hlavách vašich kolegyň a kolegů a na které by ostatní možná museli později přicházet znova.
Ještě větší transparentnost
U projektů, kde je důležité mít veřejně dostupný záznam o provedené analýze, se může hodit projekt archivovat v repozitáři např. na Zenodo nebo OSF – tím zdokumentujete nejen data, ale i celý projekt; je to forma knowledge managementu viz (-> návod).
Další zdroje
České pojednání o tématu správy dat najdete v knize Krejčí a Leontiyeva (2012), základní principy najdete i na webu Českého sociálně vedního datového archivu; tamtéž i návod na tvorbu tzv. plánu správy dat pro společenskovědní projekty. Užitečné mohou být i prezentace z nedávného semináře ČSDA k tématu.
Příklad dlouhodobé správy dat pro další využití je Český sociálně vední datový archiv (ČSDA), kde v prohlížeči datových sad najdete i způsob zaznamenání metadat, ze kterého se lze inpirovat.
K dokumentaci se mohou hodit standardy tzv. Dublin core metadat - sice působí technicky, ale když je dokážete využití, nebudete vynalézat to, co už někdo vymyslel.
Alternativní přístup k dokumentaci dat a související nástroje nabízí Data Documentation Initiative.
Pragmatický standard dokumentace tabulkových datových sad používá britská státní správa.
K dokumentaci datasetů viz Gebru et al. (2021), též kap. 10 v Alexander (2023).
Kompletní průvodce pro správu dat v kontextu výzkumu je Data Management Expert Guide od CESSDA.